Midwest Defenders Pt. 2

Following up on last week's blog, we learn how Jesse programmed his team's submission for Open CV's Spatial AI competition.
Team Midwest Defenders Continued...
Jesse Brockmann is a senior software engineer with over 20 years of experience. Jesse works for a large corporation designing real-time simulation software, started programming on an Apple IIe at the age of six and has won several AVC event over the years. Make sure you stay up-to-date with our blog to read all about Jesse's work!
Read the last blog on Jesse's LEGO build if you are interested in the first part of this project! With the LEGO part of the build complete, now the endeavor switched to code development. The first step was to install the python depthai and run some provided examples. This proved to be successful, so next the process of building a custom AI and acquiring the images required for training was started. We printed some signs to use and took many images of these signs to train the neural network. The signs were printed in ABS, and the images on the signs were printed on photo paper and glued on. The signs were designed to be of similar scale to the Land Rover, and based on real road signs.
Initially there were two possible alternatives for designating the course. One was using tape as a line, or possibly large pieces of paper with lines drawn. The second was to use something like poker chips laid out in a line. This was ultimately chosen as less destructive, more robust, and easier to set up and teardown.

Completed rover with some signs and markers ready for testing
50+ images were taken of the signs and tokens in different lighting and angles. The images were then labeled using labelimg. A MobileSSD neural network was configured and trained locally on a desktop machine with a Nvidia 3060 Ti using example code linked from this webpage. This was then used with the depthai example python code to see the results of the training. It was detecting objects but with a low certainty and many false positives.
Research was done and it was determined that a Yolo V3 or Yolo V4 network would improve performance, and the above website also provided a link to a jupiter notebook setup for a Yolo V3/V4 framework known as darknet. The code was converted into a local python script, and anaconda was used to provide the python environment used for running on a Windows 10 machine. The label data required by Yolo is different from that of MobileNet SSD, so a python script was used to convert between the two formats.
Training was started using Yolo V4, but it was clear the data was not properly formatted for Yolo. After investigation we found the Roboflow website, and realized this could provide a much quicker path to having robust training data. All current images and labels were uploaded to Roboflow, augmentation was added and then training data was exported from roboflow that required no processing for use by darknet. This initial data was trained in Roboflow for validation, and also offline by darknet. The results showed promise, and it was determined this would be the course moving forward.
After this initial success we were contacted by Mohamed Traore from Roboflow, and he helped us improve our image augmentation settings and gave suggestions on how to improve the training. The result of this was a much more robust neural network with a very high detection rate with low false positives. Once this framework was in place 250+ more images were added to improve the detection rates for a total image count of over 3000 with augmentation.

Now that the neural network was working, it was time to interpret the data from the Oak-D-Lite and use it to make command decisions for the rover. A basic rover framework written in C++ was created from scratch and designed to be modular to allow for subsystems to be added and removed with minimal effort. This rover framework runs on Windows, Linux and also higher end microcontrollers like the Teensy with a light version of the framework.
The following subsystems were created for the Teensy microcontroller
- Encoder - Reads pulses from hall effect sensor to determine distance traveled by rover
- IMU - Reports the current heading of the rover in a relative system using BNO-055 IMU with zero as the initial heading and 500 meters for x and y
- Location - Use Encoder and IMU data to find the relative location of the rover (Dead Reckoning)
- PPM Input - Designed to take RC inputs and translate into -1.0 to 1.0 signals for use by other systems
- Teensy Control - Sends the PWM output to the servo and ESC
- Command - Makes the low level command decisions for the rover. The Pi provides a desired heading and speed and this subsystem uses that information to command the servo and ESC
- Serial - Used for communication with the Pi

The following subsystems were created for the Pi or Windows machine
- Curses - Text/Console based UI to control and display rover information
- Image - Use DepthAI to find objects, and also display windows with detection data and camera images
- Image Command - Use the detection data to determine the heading and speed the rover should travel
- JoyStick - Read manual commands from a usb joystick or bluetooth joystick (not currently functional on windows)
- Serial - Used for communication with the Teensy
We are not going to go into details for these subsystems other than the Image and Image Command as those are what make this an Oak-D rover instead of a generic rover.
The Image subsystem and a DepthAPI class provide the interface to the Oak-D-Lite. DepthAPI is a C++ class based on provided example code, modified to meet the needs of the Image subsystem. The main purpose is to provide detection data and allow debugging by providing a camera feed with detection overlay or the ability to record images or videos for later inspection.
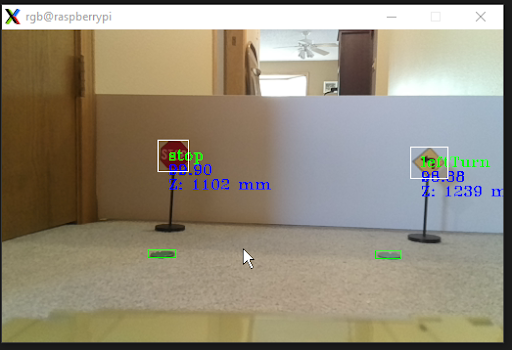
Real time image from rover during testing
The Image Command subsystem uses the heading of the rover from the Teensy, also with the detection data to determine a course of action for the rover. It looks for objects and determines a heading to those objects by taking the current heading and atan2 of the marker X and Z position and returns a heading to intersect with the object. This along with a constant speed is sent to the Teensy to implement those commands to its best ability. Turn signs are used to allow the rover to take tighter turns then the markers will allow. A very tight turn isn’t possible using markers due to the limited field of view as the markers are not visible during these turns. When a left or right turn sign is in view the rover aims for these signs, and then when 0.95 meters from a sign does a 90 degree turn relative to the current heading.
Once the new heading is achieved the rover goes back to looking for markers. U-Turns are similar however the turn consists of two 90 degree turns instead of one. When using markers to navigate, the algorithm will do the following. If only one marker is in view it will try to keep the rover lined up to go directly over the marker. As more become available it will use the average location between two markers to decide its path. For two markers it’s in between those, for three or more it’s in between the second and third markers. This provides some look ahead information to allow the rover to make tighter turns then it could otherwise. A more advanced algorithm could be added to keep the point of interest the rover is steering towards at a constant distance in front of the rover by using all known marker locations to interpolate or extrapolate this point.
When a stop sign is detected the rover will aim for the stop sign and stop 1.1 meters from the stop sign, and automatically end navigation. Other signs such as parking, no parking and dead end signs could also be added to further enrich the navigation possibilities, but given the 3 month time frame were not pursued further.
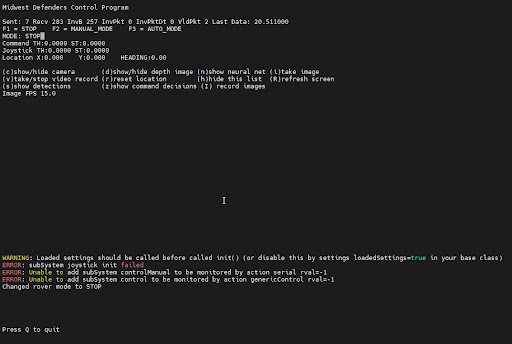
Curses based data display and rover control program
Thanks for reading! We have the last part of this series coming out in a few days, so be sure to check back in to find out the Midwest Defenders wrapped up their project!







{kind=link}