It seems like everyone and their mother is talking about AI these days. And for good reason: a lot of AI-driven tools are becoming more accessible than ever, and they've advanced past the alarmingly innacurate first iteration of the speech-to-text voicemail transcription feature on the iPhone. Machine learning is a subset of AI, and it impacts your life in more ways than you may realize. As a SparkFan, learning more about it could also get you to start thinking about using it in your projects, and how your data could be used for advanced software applications.

This is how the AI takeover will begin.
Since machine learning is on trend right now, you may think it’s just another buzzword people in the industry are throwing around when they want to sound smart or cutting-edge. (Personally when I try to sound cutting-edge, I just insert a mention of the floppy disk into casual conversation, but to each their own.) However, machine learning is not only a very real up-and-comer, it's already here. Knowing how it works is helpful not just to the tech enthusiast, but to anyone living in our information-centric society.
By definition, Machine Learning is "the use and development of computer systems that are able to learn and adapt without following explicit instructions, by using algorithms and statistical models to analyze and draw inferences from patterns in data." That's a large umbrella that describes a lot of current technology we see every day. This blog is the first installment of a series all about machine learning, its impact, and what it could mean for you. Today we'll be talking about the fundamentals of ML, the different types of ML, and how they're used.
Fundamentals of ML
Data
Machine Learning relies heavily on data because it is a data-driven approach to problem solving and decision making. The fundamental concept behind Machine Learning is to enable computers to learn patterns, make predictions, and improve their performance based on experiences gained from data. By exposing ML algorithms to a diverse and representative dataset, they can discover underlying patterns that enable them to generalize and make accurate predictions on new data.
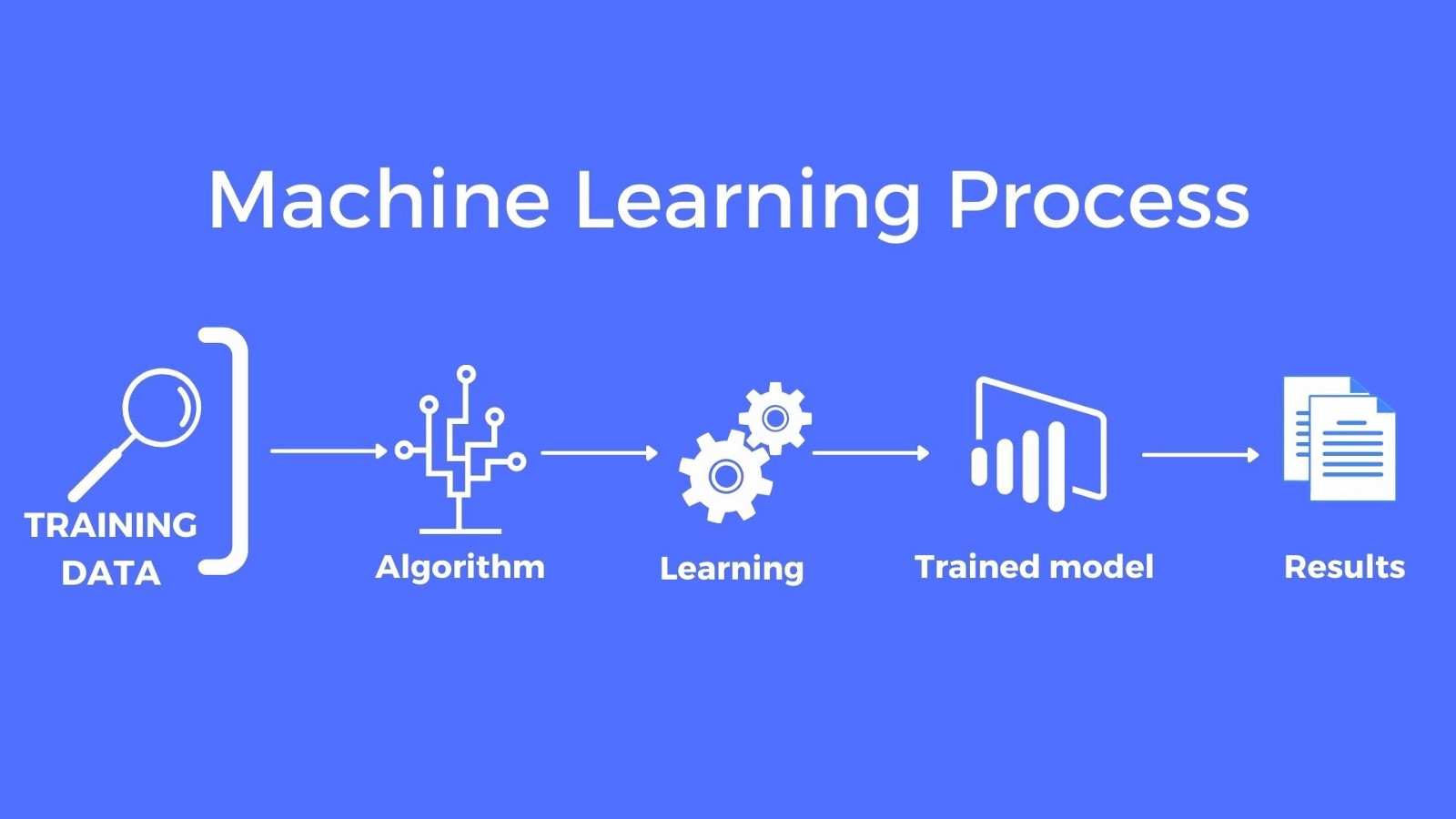
If there's no data, there's nothing to learn. Source: Mapendo
In many ML tasks, the quality and relevance of features (input variables) significantly impact the model's performance. Data provides the necessary information to extract meaningful features that are essential for effective learning and decision-making. During the training phase, ML models adjust their internal parameters to minimize the discrepancy between their predictions and the actual data (labels). The more data the model is exposed to, the more it can fine-tune its parameters, leading to improved performance and generalization. The larger the dataset, the more accurate the results.
In complex tasks such as image recognition, natural language processing, or deep learning, the models often have millions of parameters that need to be estimated. Adequate data is required to optimize these parameters effectively and prevent overfitting or underfitting. However, while the amount of data is critical in Machine Learning, the quality of the data is equally vital. Biased, noisy, or insufficient data can lead to poor or biased models. Preprocessing and careful curation of data are necessary steps to ensure that the ML models can learn and generalize effectively, leading to more reliable and accurate outcomes.
Algorithms
In addition to being the higher power behind your highly curated feed on Instagram and TikTok that knows you're out of toilet paper before you do, an algorithm is a finite set of instructions needed to perform a task or solve a problem. If you've ever taken CS 101, you've probably heard the peanut butter and jelly problem: tell a computer how to make a peanut butter and jelly sandwich. It's a useful exercise that shows you a computer can't fill in gaps of knowledge or context like we can. You can't just tell it "get two pieces of bread out" because it doesn't know what bread looks like, where it's stored in your kitchen, or where to put it. In order to accurately get your sandwich, you have to be painfully explicit in your instructions.

This robot has never even heard of bread, so he's doing pretty well, all things considered. Source: Inspirit Scholars
That's an example of an algorithm - rigorous, defined instructions to do something specific. Computers aren't smart, they can't think for themselves and they can't do anything the programmer doesn't make possible for them. However, they are extremely fast, and that's why we use them. Computer scientists optimize algorithms for speed and simplicity, and the machine will do exactly as it's told to solve complex calculations and automate decisions and tasks.
In machine learning, the goal is to get the computer to discover its own algorithm by learning from a dataset without explicit programming. These algorithms want to reach a point where they can accurately classify new data based on old data, or make decisions from the data they're receiving based on previous events. The past data trains the algorithm on how to process the new data. Using an iterative process, it keeps checking its predictions off known solutions, then alters the model to fit. Given enough examples of a properly assembled peanut butter and jelly, it might be able to discern the recipe.
A core assumption of machine learning that enables this process is generalization - if something has worked 99 times before, we can assume it will work the 100th time it's attempted. If an image with certain properties has been accurately labeled as a crosswalk 99 times, we can assume the next time the algorithm encounters a similar image it will classify it as a crosswalk.
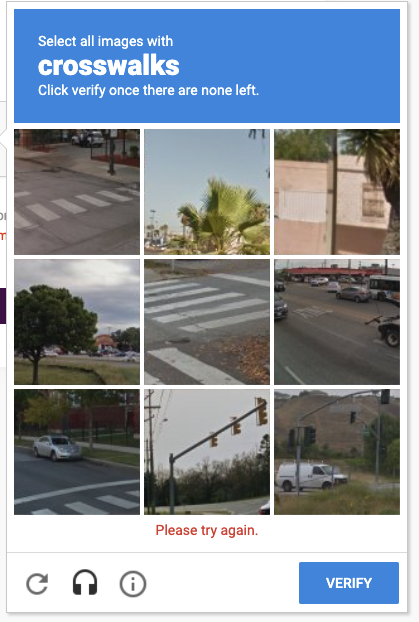
Every captcha you've ever done has been feeding a model. Thank you for your service.
Models
The ML algorithm is the mechanism that learns from data, while the ML model is the learned knowledge that can be applied to new data for making predictions or decisions. The algorithm processes the training data, adjusting its internal parameters to capture patterns, and produces the model as its end result. Trained through ML algorithms, models use those patterns and relationships within the training data, allowing them to generalize and apply that knowledge to real-world scenarios.
Once the model is trained, it can be deployed and used to make predictions or perform various tasks in autonomous vehicles, image recognition, and natural language processing. By creating meaningful feature representations, models transform raw data into actionable information, making them valuable tools in optimizing tasks and improving efficiency. Their versatility allows deployment across different systems, enhancing automation and aiding in decision-making processes.
There are many different types of models, and many are specialized for specific applications. Here are some of the models commonly used in ML:
Linear Regression: Establishes a linear relationship between input features and a continuous target variable, making it suitable for predicting numerical values. The model finds the best-fit line that minimizes the sum of squared errors between the predicted values and the actual target values. The slope and intercept of the line represent the model's learned coefficients, which determine the relationship between the features and the target variable. Linear Regression is used in various ways, such as predicting house prices based on features like size, location, and number of rooms. It is also used in finance to forecast stock prices or in weather forecasting to predict temperature trends.
Logistic Regression: A binary classification model that predicts the probability of an input belonging to one of two classes. It uses a logistic function to map input features to probabilities, which are then thresholded to make the final class prediction. The model's coefficients represent the strength of the relationship between features and the likelihood of belonging to a specific class. Logistic Regression is often used in medical diagnosis, such as predicting the likelihood of a patient having a certain disease based on medical test results. It is also utilized in spam email filtering, sentiment analysis, and credit risk assessment.
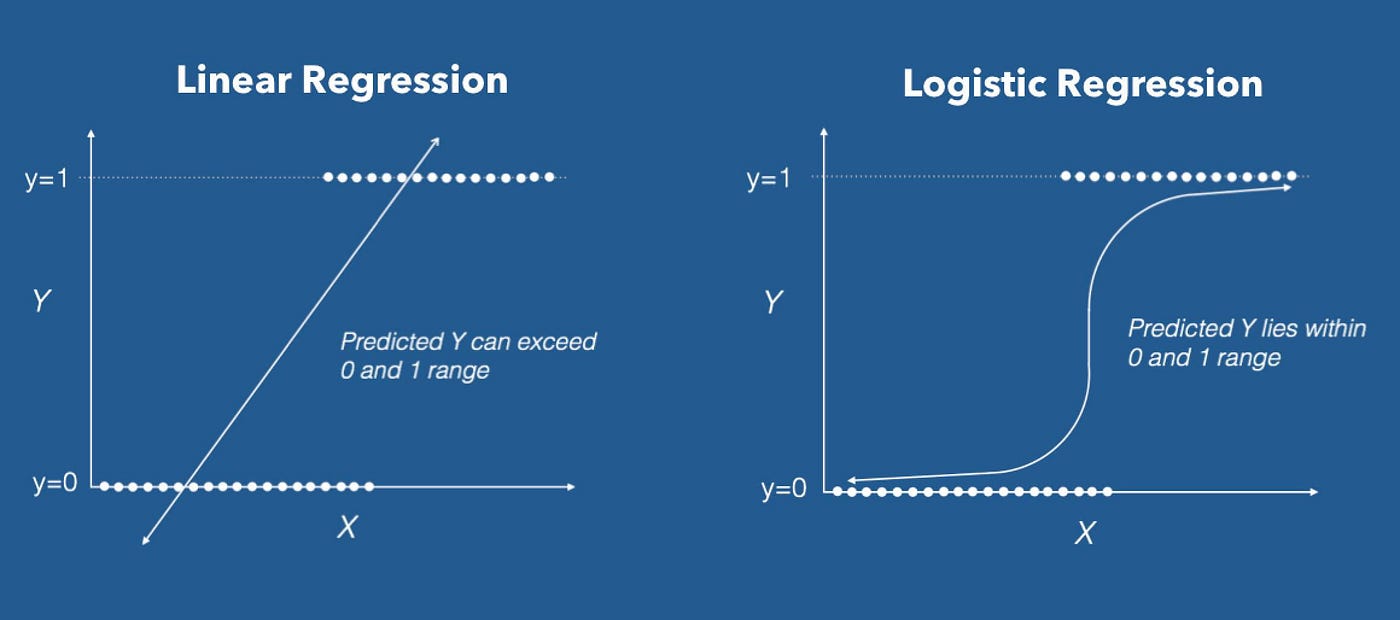
Comparison between linear and logistic regression. Source: Towards Data Science
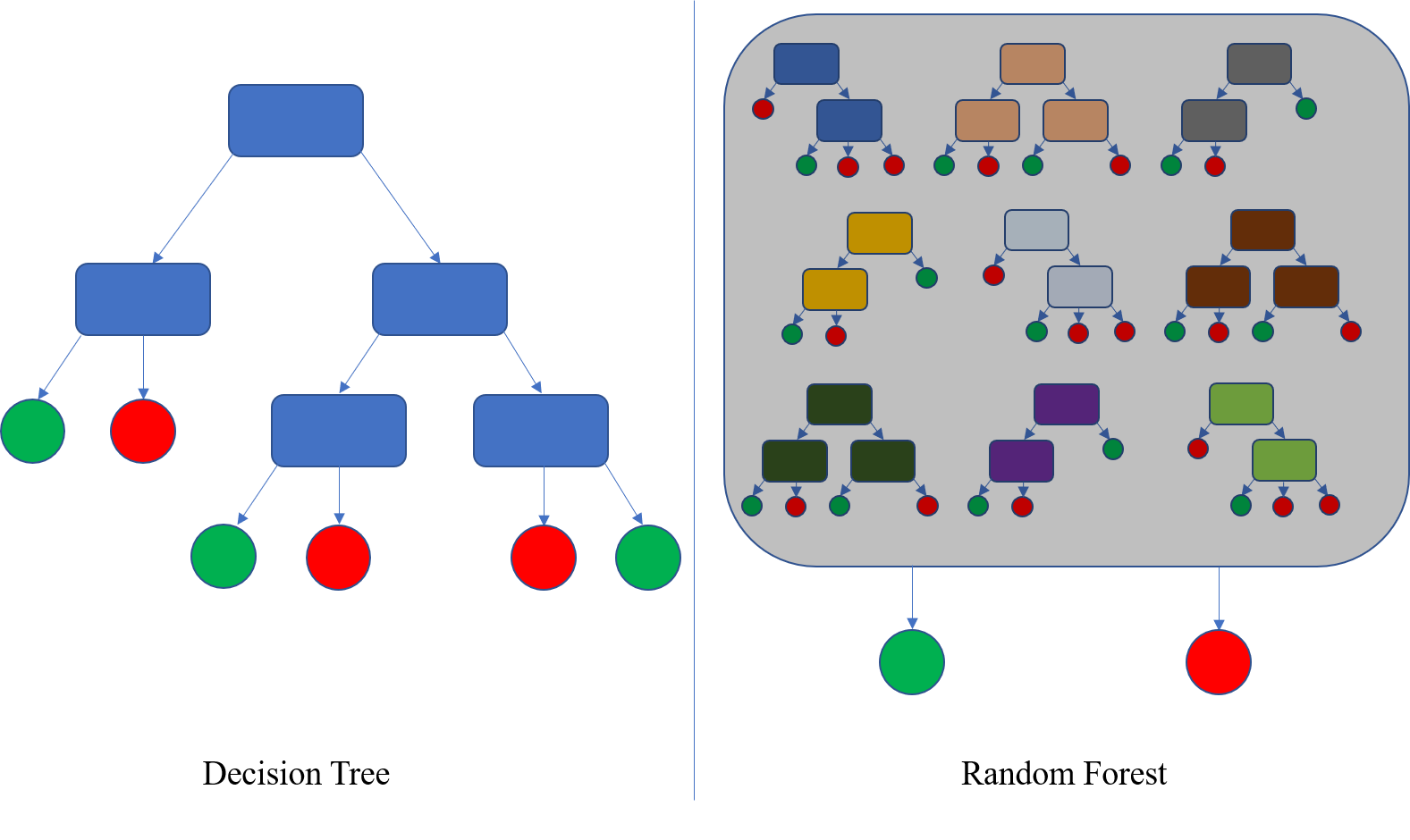
Decision Trees: Intuitive ML models that create a tree-like structure based on feature splits to make decisions. Each internal node represents a feature, each branch a decision rule, and each leaf node an output class or value. The model selects the best features and thresholds to split the data into subsets that are homogenous in terms of the target variable. Decision Trees are popular for classification and regression tasks, as they are easy to understand and interpret. They find use in customer segmentation, disease diagnosis, and product recommendation systems.
Random Forest: Continuing with the arboreal vibes, Random Forest is an ensemble learning technique that combines multiple decision trees to improve accuracy and reduce overfitting. It creates multiple decision trees and combines their predictions to make the final decision. Each tree is trained on a random subset of the data with replacement, and feature subsets are considered for each split, ensuring diversity among the trees. Random Forest is effective in applications like image recognition, where it handles complex and high-dimensional data. It's also utilized in financial forecasting and sentiment analysis.
- Support Vector Machines (SVM): A powerful ML model used for classification and regression. It can assign categories to new examples given labeled categories. SVM maps examples to points in space, then maximizes the gap between them, seeking to find the optimal decision boundary. SVM is used in text classification like spam detection and sentiment analysis, image recognition, and bioinformatics.
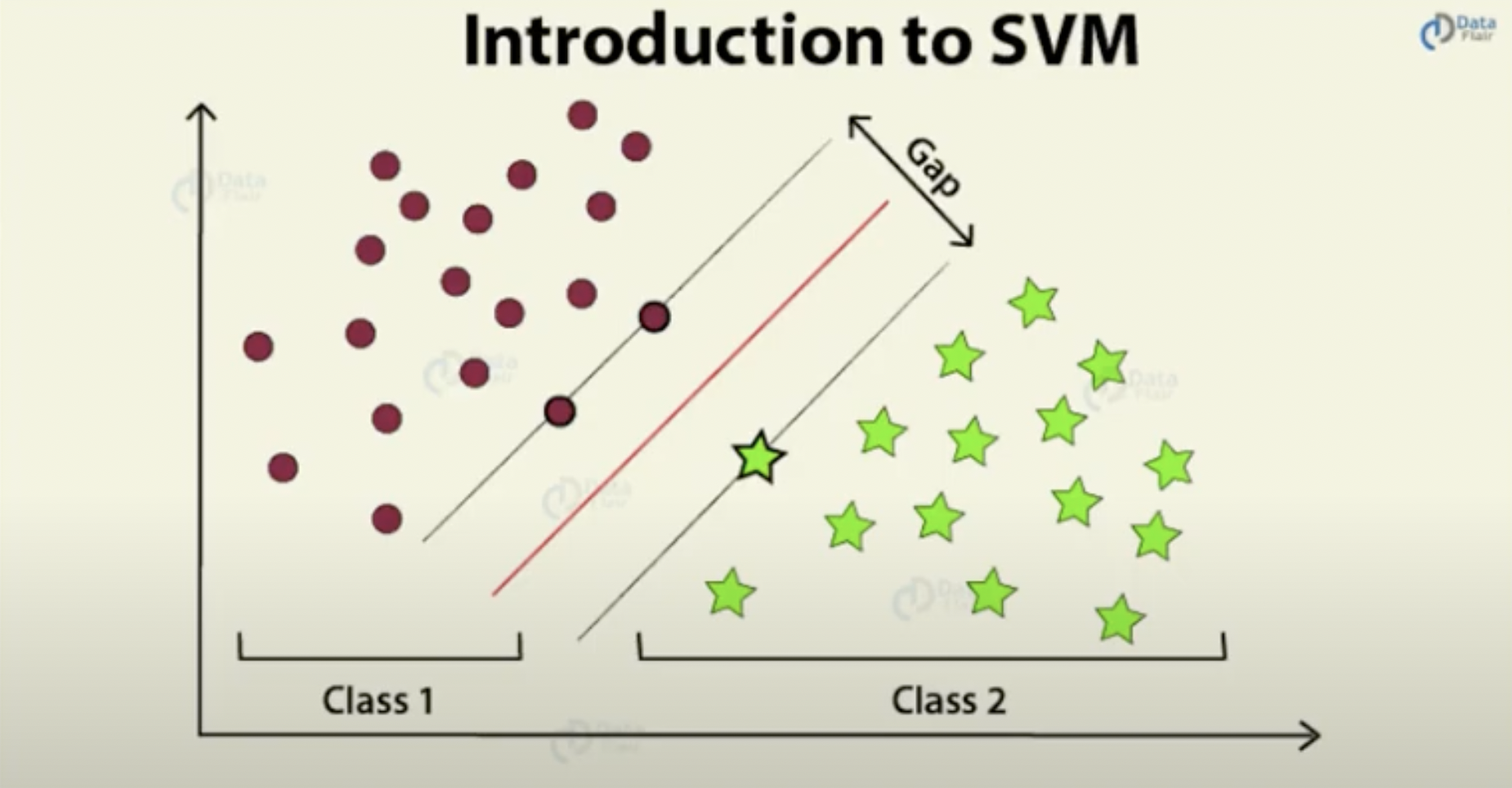
Where new points lie within the gap will tell the model how to categorize them. Source: Data Flair
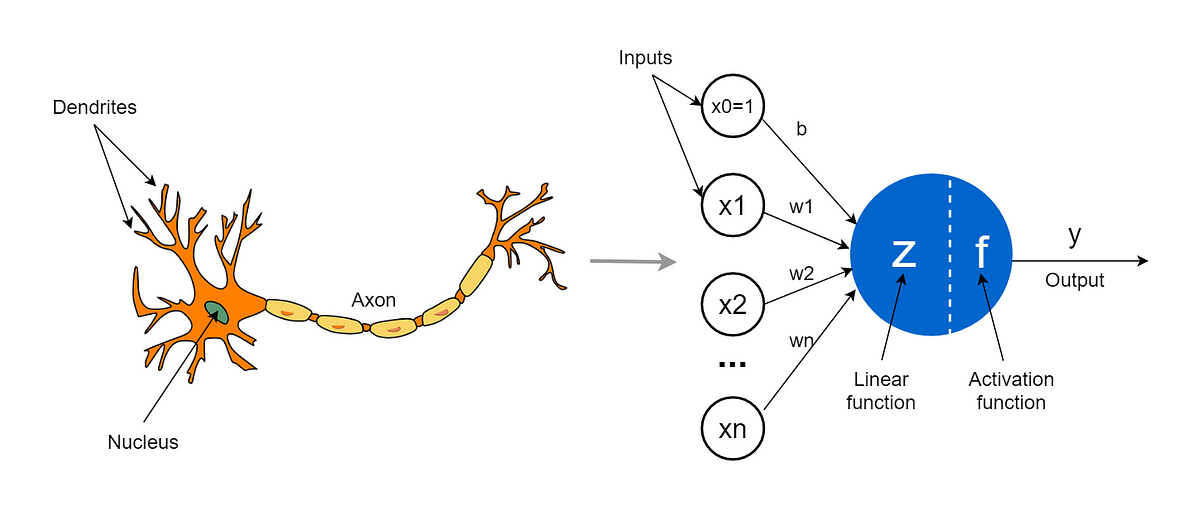
- Artificial Neural Networks (ANN): Inspired by the human brain and consist of interconnected layers of artificial neurons. They are the foundation of Deep Learning, which uses neural networks with multiple layers. ANN employs forward and backward propagation to learn complex feature representations from the data, allowing them to handle high-dimensional and nonlinear relationships. ANN is widely used in image and speech recognition, natural language processing, and autonomous vehicles. They have shown exceptional performance in tasks like object detection, language translation, and playing strategic games.
- K-Means Clustering: An unsupervised learning algorithm used for clustering. It groups n data points into k clusters based on their similarity - each datapoint belongs to the cluster with the nearest mean. The algorithm starts with randomly initialized centroids for each cluster, then iteratively assigns data points to the nearest centroid and recalculates the centroids' positions until convergence. K-Means is used for targeted marketing campaigns, image compression, and anomaly detection. It is also used in various data exploration and visualization tasks.
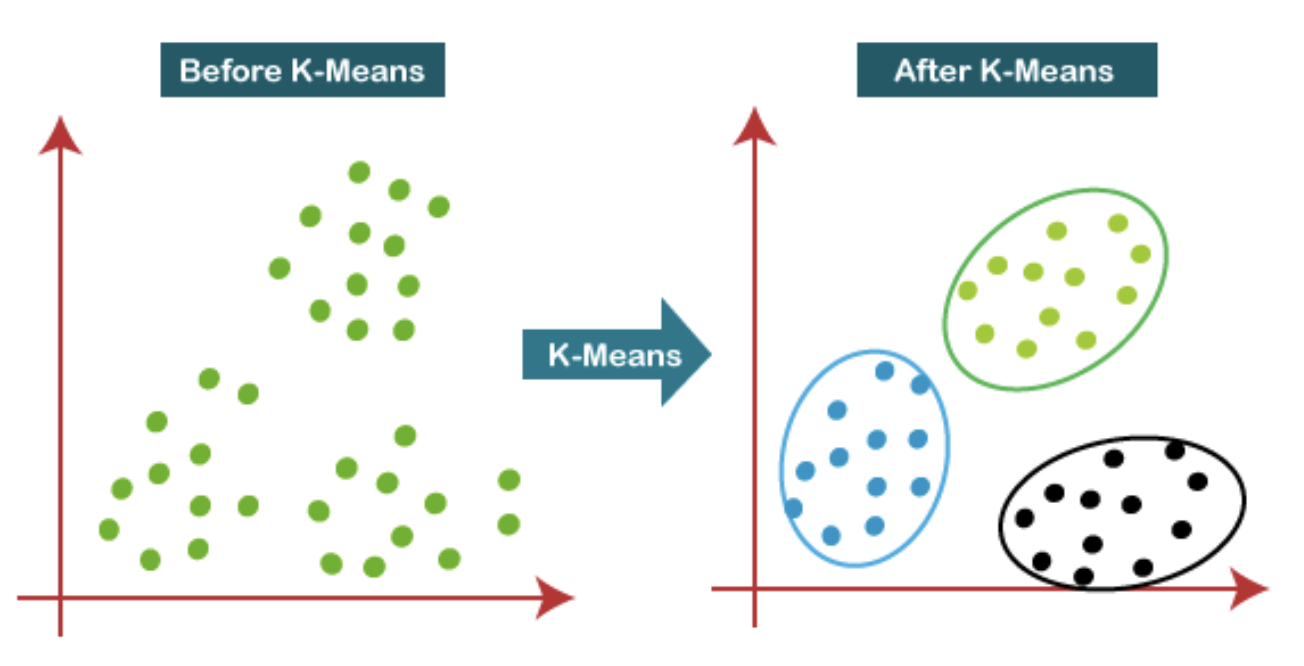
Source: Java T Point
Types of ML
The field of ML is constantly developing and changing, but there are three main types that most ML methods fall under.
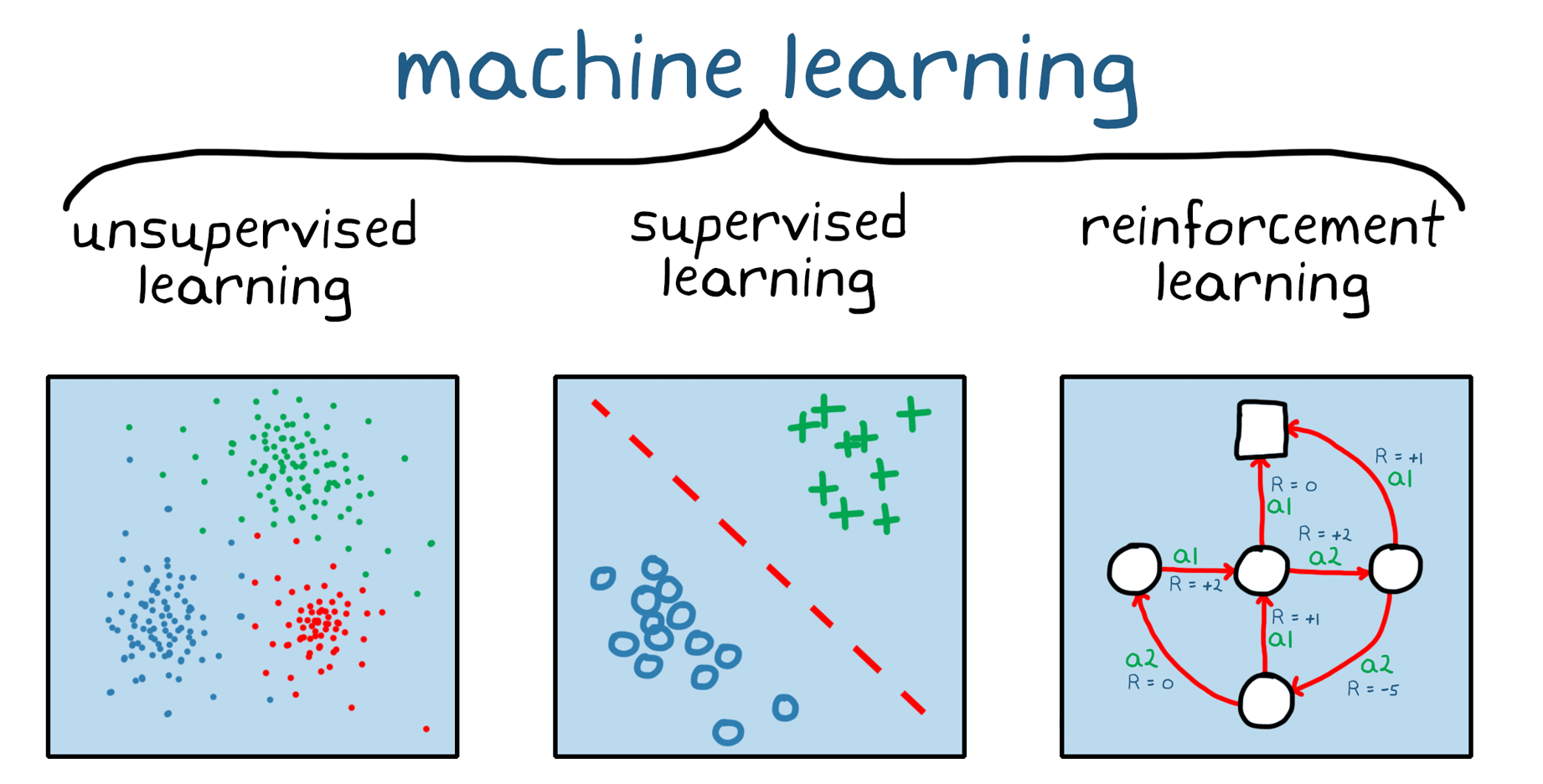
Source: Math Works
Supervised Learning: Training Data and Labels
Supervised learning is a type of machine learning where the model is trained on a labeled dataset, meaning that each input data point has a corresponding output label or target value. The goal of supervised learning is for the model to learn the relationship between the input features and their corresponding labels so that it can make accurate predictions on new data it's never seen before. During training, the model adjusts its internal parameters based on the provided labeled examples, minimizing the error between its predictions and the true labels. Supervised learning is commonly used for tasks like classification, where the model assigns input data to predefined categories, and regression, where the model predicts continuous numerical values.
Real life example: galaxy classification. Galaxy Zoo began as a way to crowdsource the labeling of training data. Although it started with galaxy images, Zooniverse now has many other classification labeling projects going, such as handwriting transcription, wildlife monitoring, and gravitational wave detection.

Source: Galaxy Zoo
Unsupervised Learning: Clustering and Dimensionality Reduction
Unsupervised learning is a type of machine learning where the model is trained on an unlabeled dataset, meaning that the data points do not have corresponding output labels. In unsupervised learning, the model seeks to find patterns, structures, or relationships within the data without specific guidance. Common tasks in unsupervised learning include clustering, where the model groups similar data points together based on their similarities, and dimensionality reduction, where the model reduces the number of features while preserving important information. Unsupervised learning is valuable for data exploration and finding hidden patterns in complex datasets.
Real life example: climate analysis in Somalia. Researchers used unlabeled data in the form of satellite images to find differences indicative of loss of vegetation.
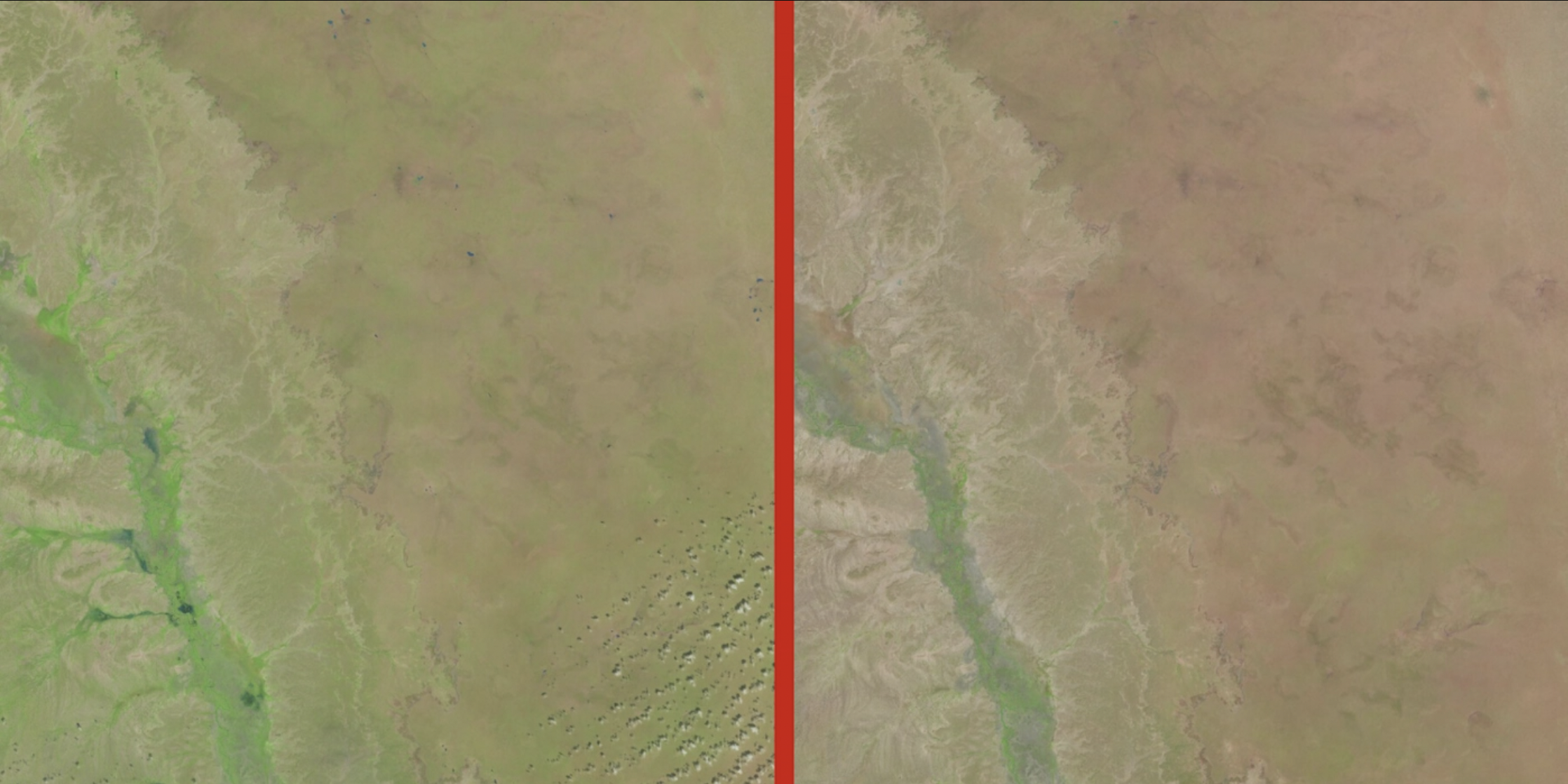
Source: Omdena
Reinforcement Learning: The Role of Rewards and Agents
Reinforcement learning is a type of machine learning that deals with decision-making in an environment where an agent interacts with the environment to achieve a specific goal. The agent receives feedback in the form of rewards or penalties based on its actions, guiding it to learn from trial and error. The objective of reinforcement learning is for the agent to learn the optimal policy or strategy that maximizes cumulative rewards over time. The agent takes actions based on what it has learned and continually updates its decision making process. Reinforcement learning is used in applications such as robotics, game playing, resource management, and autonomous vehicles, where the agent must make sequential decisions to achieve its goals.
Real life example: traffic signals. A research group experimented with using reinforcement learning to optimize traffic signals in their environment.
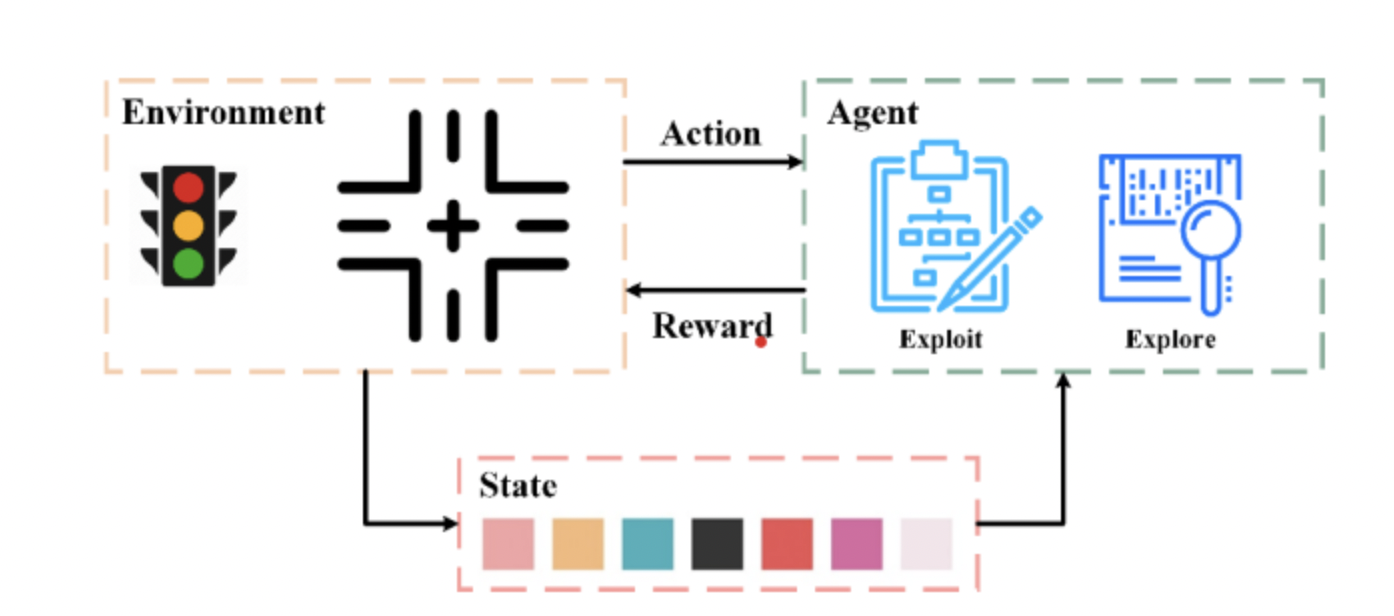
Source: Li, Xu, Zhang
Stay tuned in the coming weeks for more about machine learning's history, TinyML, and how this revolution will affect you!
Using ML in your work? We want to hear about what type you're utilizing! Let us know in the comments.









{kind=link}
Great article! What about paper tape??
"I just insert a mention of the floppy disk into casual conversation"
Floppy disk? Such a modern concept! I usually insert mention of the punched card! :-) :-) :-)