The history of machine learning reflects humanity's quest to create computers in our own image; to imbue machines with the ability to learn, adapt, and make intelligent decisions.
We're talking more about Machine Learning, but today we're going back in time. Right now we're in the information age, and many young people (myself included) can't imagine a society before phones, constant data collection and the information economy.
Spanning decades of innovative research and technological breakthroughs, there was a remarkable progression from Machine Learning's early theoretical foundations to the transformative impact ML now has on modern society. The history of machine learning reflects humanity's quest to create computers in our own image; to imbue machines with the ability to learn, adapt, and make intelligent decisions. This is a journey that has reshaped industries, redefined human-computer interaction, and ushered in an era of unprecedented possibilities.

Alan Zenreich, Creative Black Book: Photography (1985)
For what Machine Learning is, you can take a look at What is Machine Learning?, the previous blog in this series. There, I also define the different types of ML which will be further discussed here. This is an overview, so if I missed your favorite ML history milestone, drop it in the comments!
Early Concepts and Foundations
You may think of AI and ML as very recent breakthroughs, but they've been in development longer than you might think. And, like any great scientific achievement, it wasn't a single person writing code in a dark room by themselves 20 years ago - each person laid a stepping stone (shoulders of giants, etc etc). As soon as computation arose as a concept, people were already starting to wonder how it would compare to the most complex system we knew -- our brains.
The Turing Test
Mathematician and pioneering computer scientist Alan Turing had a large influence on the inception of machine learning. He proposed the Turing Test in his 1950 paper "Computing Machinery and Intelligence." It's a test of a machine's ability to exhibit human-like intelligence and behavior. The test is designed to assess whether a machine can imitate human conversation well enough that an evaluator cannot reliably distinguish between the machine and a human based solely on the responses they receive.
In the Turing Test, a human evaluator engages in text-based conversations with both a human participant and a machine (often called the "imitation game"). The evaluator's goal is to determine which of the two participants is the machine and which is the human. If the evaluator cannot consistently distinguish between the machine and the human based on the conversation, the machine is said to have passed the Turing test and demonstrated a level of artificial intelligence and conversational skill comparable to that of a human.
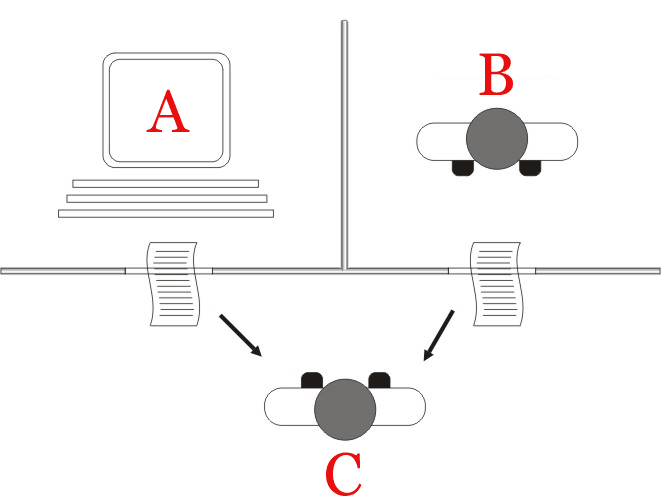
In the Turing Test, the observer (C) wouldn't be able to tell the difference between the two outputs from the machine (A) or the human participant (B) for a machine that passed.
However, the test is subjective. Sometimes someone may think a computer has passed, when someone else knows a language model trained on a large amount of human language might say things that humans do. We also should ask if imitating human language is the same thing as (or the only marker for) intelligence, and if our sample size of 1 for examples of what we call intelligence is making our approach too close-minded for what we perceive to be on our level. Despite criticisms, for 1950 when computation as we know it was still in its early stages, this thought experiment had a huge influence on the attitudes toward a machine's ability not just to think, but to think as we do.

Worth a shot. Source: xkcd comics
Playing Checkers
Arthur Samuel, a pioneer in artificial intelligence and computer science, worked at IBM and is often credited with creating one of the earliest examples of a self-learning machine. Samuel's program, developed between 1952 and 1955, was implemented on an IBM 701 computer. The program employed a form of machine learning known as "self-play reinforcement learning." It played countless games of checkers against itself, gradually refining its strategies through trial and error.

Arthur Samuel and his thinking machine. Source: IBM
As the program played more games, it accumulated a growing database of positions and the corresponding best moves. The program used this database to guide its decision-making in future games. Over time, the program improved its play, demonstrating the ability to compete with human players and even occasionally win against them.
Arthur Samuel's work on the Checkers-Playing Program marked a significant milestone in the early history of ML. It showcased the potential for computers to learn and adapt to complex tasks through iterative self-improvement. This project laid the groundwork for later developments in machine learning algorithms and techniques, and it highlighted the practical applications of AI in domains beyond mere calculation and computation.
The Perceptron
The perceptron was one of the earliest neural network models and a significant development in the history of artificial intelligence and machine learning. It was introduced by Frank Rosenblatt in the late 1950s as an attempt to create a computational model that could mimic the basic functioning of a biological neuron. The perceptron was intended to be a machine, but became an algorithm for supervized learning of binary classifiers.
The perceptron is a simplified mathematical model of a single neuron. It takes input values, multiplies them by corresponding weights, sums them up, and then applies an activation function to produce an output. This output can be used as an input for further processing or decision-making.
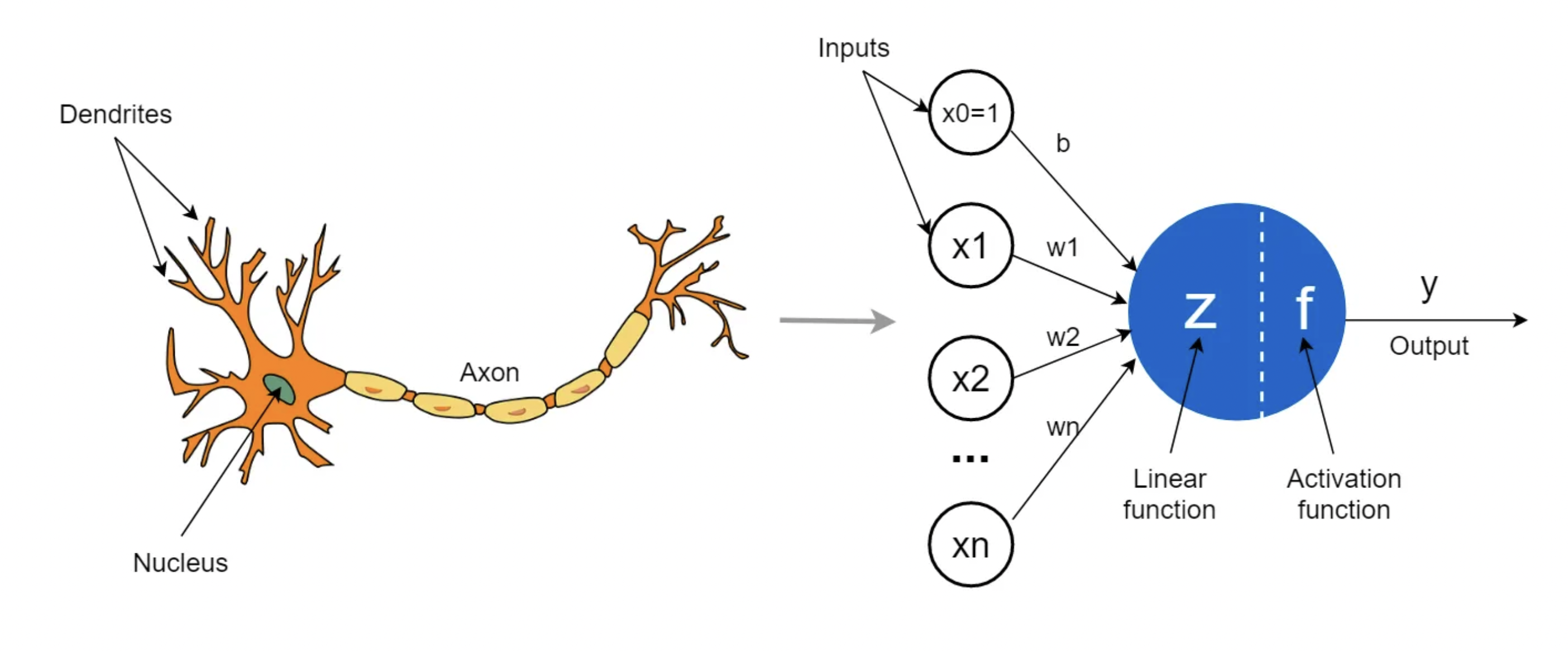
The perceptron took inspiration from the form and function of the neuron. Source: Towards Data Science
The key innovation of the perceptron was its ability to adjust its weights based on input data and target output. This process of weight adjustment is achieved through a learning algorithm, often referred to as the perceptron learning rule. The algorithm updates the weights to reduce the difference between the predicted output and the desired output, effectively allowing the perceptron to learn from its mistakes and improve its performance over time.
The perceptron laid the foundation for the development of neural networks, which are now a fundamental concept in machine learning. While the perceptron itself was a single-layer network, its structure and learning principles inspired the creation of more complex neural architectures like multi-layer neural networks. It also demonstrated the concept of machines learning from data and iteratively adjusting their parameters to improve performance. This marked a departure from traditional rule-based systems and introduced the idea of machines acquiring knowledge through exposure to data.
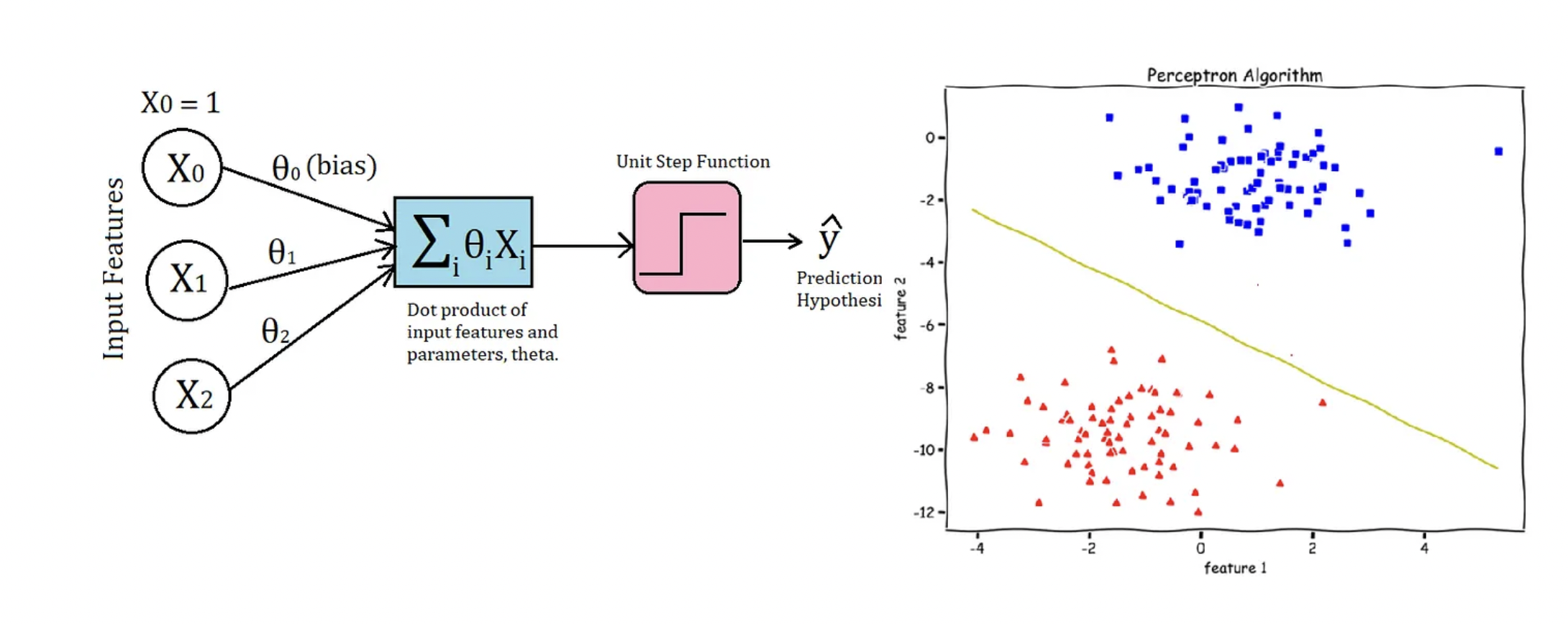
The perceptron algorithm is a binary classifier that works with linear decision boundaries. Source: Towards Data Science
However, the perceptron had limitations. It could only learn linearly separable patterns, which meant that it struggled with tasks that required nonlinear decision boundaries. Despite that, the perceptron's introduction and subsequent developments played a crucial role in shaping the trajectory of machine learning as a field. It laid the groundwork for exploring more complex neural network architectures, reinforcement learning principles, and the eventual resurgence of interest in neural networks in the 1980s and beyond.
The AI Winters
The "AI winter" refers to a period of reduced funding, waning interest, and slowed progress in the field of artificial intelligence (AI) and related areas, including machine learning. It occurred during certain periods when initial expectations for AI's development and capabilities were not met, leading to a decrease in research investments, skepticism about the feasibility of AI goals, and a general decline in the advancement of AI technologies.
First AI Winter (mid-1970s - early 1980s):
The initial wave of optimism about AI's potential in the 1950s and 1960s led to high expectations. However, the capabilities of the existing technology did not align with the ambitious goals set by AI researchers. The limited computational power available at the time hindered the ability to achieve significant breakthroughs. Research faced difficulties in areas such as natural language understanding, image recognition, and common-sense reasoning. Funding for AI research from both government and industry sources decreased due to unmet expectations and the perception that AI was overhyped. The first AI winter resulted in a reduced number of research projects, diminished academic interest, and a scaling back of AI-related initiatives.

AI winters were kind of like Ice Ages - the really dedicated developers kept it going until the climate of public sentiment changed.
Second AI Winter (late 1980s - 1990s):
The second AI winter occurred as a reaction to earlier overoptimism and the unfulfilled promises of AI from the first winter. The period was characterized by a perception that AI technologies were not living up to their potential and that the field was not delivering practical applications. Funding for AI research once again decreased as organizations became cautious about investing in technologies that had previously failed to deliver substantial results. Many AI projects struggled with complexity, scalability, and real-world relevance. Researchers shifted their focus to narrower goals instead of pursuing general AI.
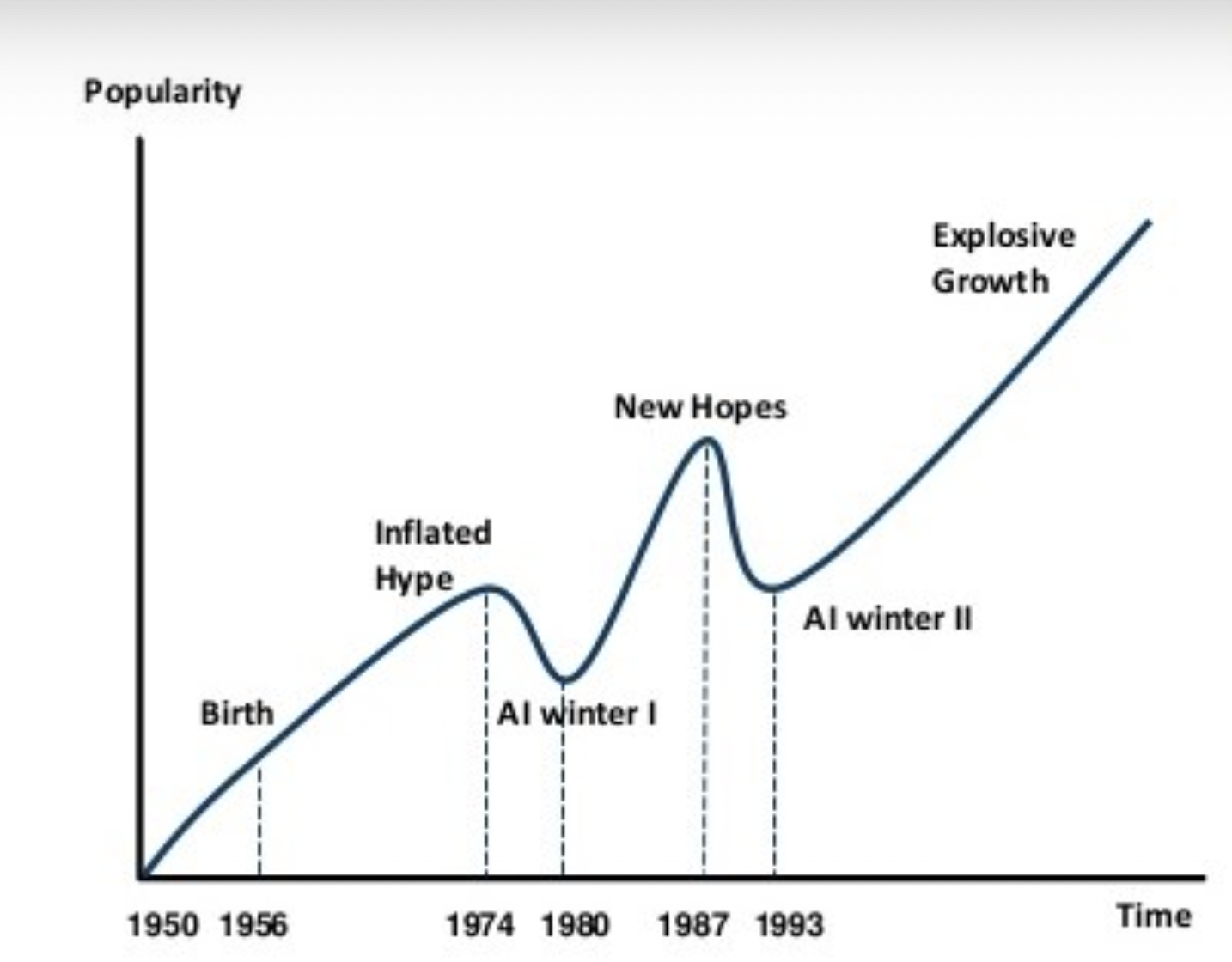
Balancing hype and output was a struggle for the field of AI. Source: Actuaries Digital
These periods weren't totally stagnant; they fostered introspection, refinement of approaches, and the development of more realistic expectations. The AI field eventually emerged from these winters with valuable lessons, renewed interest, and a focus on more achievable goals, paving the way for the growth of AI and machine learning in the 21st century.
Evolution of Algorithms and Techniques
Decision Trees
During the early stages, as the field navigated the challenges of the first AI winter in the late 1960s and early 1970s, researchers turned their attention to specialized applications, giving rise to expert systems. These systems aimed to replicate the decision-making abilities of domain experts using symbolic logic and rules to represent knowledge. By encoding expertise in the form of "if-then" rules, expert systems became adept at rule-based decision-making within well-defined domains. However, they didn't perform as well when it came to handling uncertainty and adapting to new information.
In response, the concept of decision trees emerged as a promising alternative in the early 1970s. Decision trees offered a more data-driven and automated approach to decision-making. These structures, shaped like hierarchies or family diagrams, delineated a sequence of decisions and corresponding outcomes, like a choose-your-own-adventure book. Each internal node represented a decision based on a specific attribute, while leaf nodes represented final outcomes or classifications. The construction of decision trees involved selecting attributes that maximally contributed to accurate classifications, making them interpretable and user-friendly.
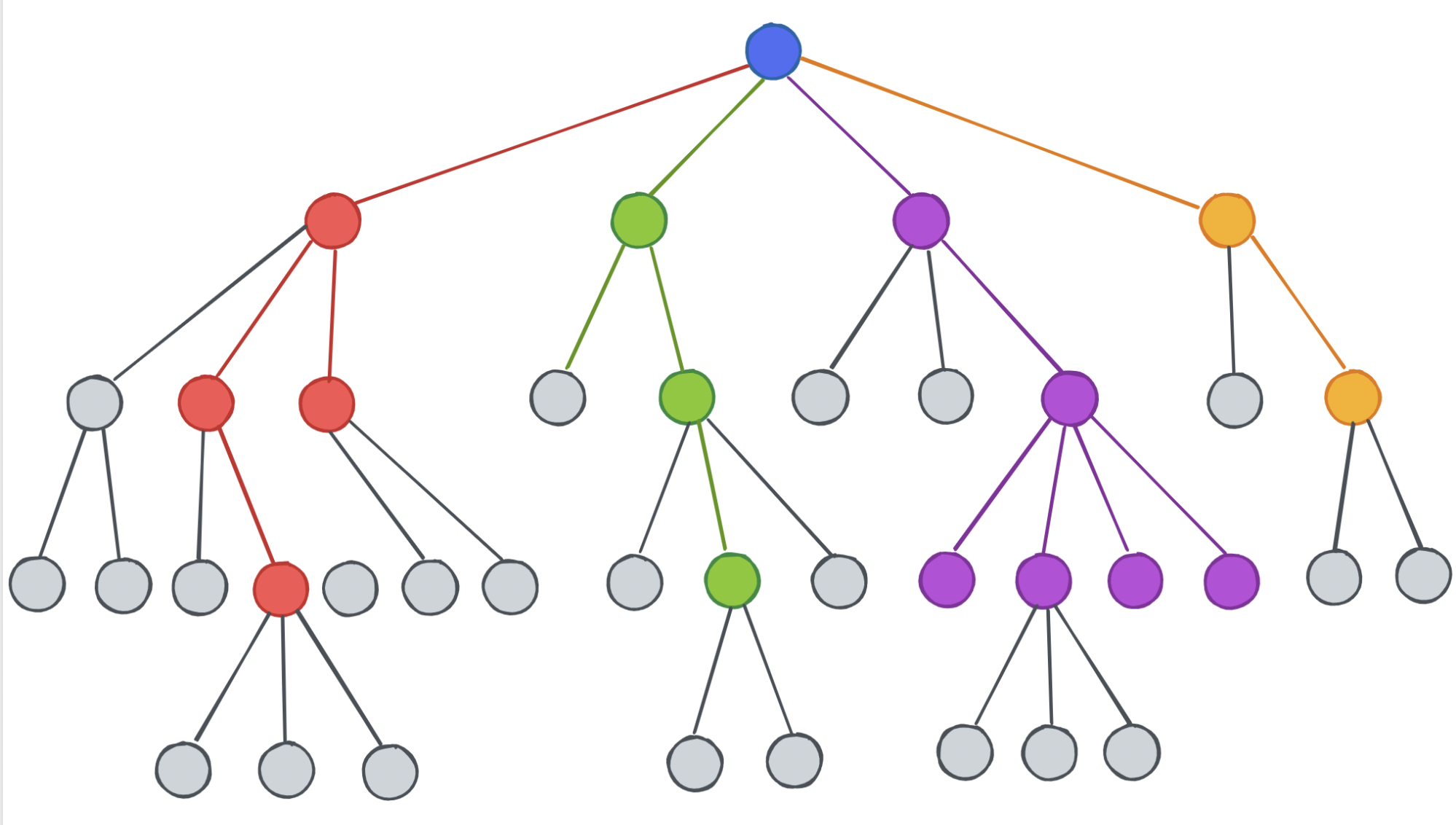
A decision tree. Source: Geeky Codes
Decision trees showcased the potential of AI and machine learning to fuse human expertise and data-driven decision-making. They have remained relevant due to their interpretability and utility in handling diverse types of data. As the AI landscape evolved, this early development provided a solid footing for the subsequent emergence of more sophisticated techniques, like ensemble methods and deep learning, allowing for more nuanced and powerful machine learning models.
Reinforcement Learning and Markov Models
Reinforcement learning emerged as an alternative to traditional rule-based systems, emphasizing an agent's ability to interact with its environment and learn through a process of trial and error. Drawing inspiration from psychology and operant conditioning, it allowed agents to adjust their behavior based on feedback in the form of rewards or penalties. Arthur Samuel's work in the 1950s provided a practical illustration of reinforcement learning in action, demonstrating how an agent could improve its performance by playing games (like checkers) against itself and refining its strategies .
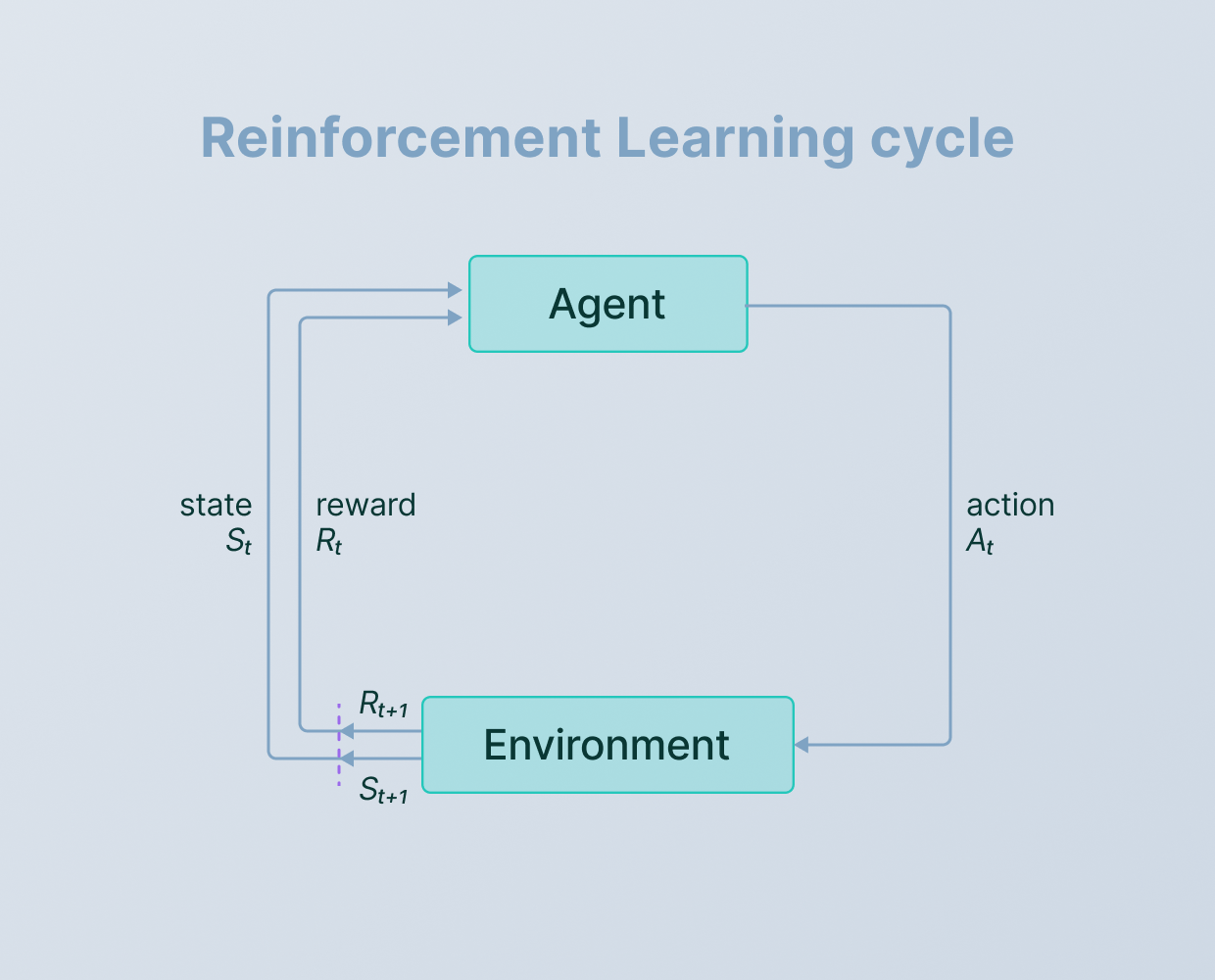
Source: V7 Labs
In parallel, the concept of Markov models, notably Markov decision processes (MDPs), provided a useful mathematical framework for modeling sequential decision-making. These models were based on the idea that the future state of a system relies solely on its present state and independent of its past states (a Markov chain is a simple display of this idea - only the current step matters to the next step). MDPs facilitated the formalization of how agents interact with environments, take actions, and receive rewards, forming the foundation for solving reinforcement learning challenges. This framework paved the way for the development of algorithms like dynamic programming, Q-learning, and policy iteration, enabling agents to learn optimal strategies over time.
These methods equipped researchers with the tools to address intricate decision-making dilemmas in fluctuating and uncertain contexts. Combining these concepts with deep learning (known as deep reinforcement learning) has expanded machine learning's capabilities, allowing agents to make sense of complex inputs.
Rise of Big Data and Computational Power
Impact of Increased Computation
The increase of computational power available to developers significantly influenced machine learning's development during the late 20th century. This era was a notable turning point, with the growing availability of more powerful hardware and the emergence of parallel processing techniques.
During this time, researchers and practitioners started to experiment with larger datasets and more complex models. Parallel processing techniques, such as the use of multi-core processors, paved the way for faster computations. However, it was the early 21st century that witnessed a more pronounced impact as graphical processing units (GPUs) designed for graphics rendering were adapted for parallel computing in machine learning tasks.
The development of deep learning models gained momentum around the 2010s. These models demonstrated the potential of harnessing significant computational power for tasks like image recognition and natural language processing. With the availability of GPUs and distributed computing frameworks, researchers could train deep neural networks in a reasonable amount of time.
Cloud computing platforms and services, such as Amazon Web Services, Google Cloud Platform, and Microsoft Azure, opened up access to massive computational resources. This accessibility enabled individuals and organizations to leverage powerful computing for their machine learning projects without needing to invest in specialized and expensive hardware themselves.

Tensor Processing Unit
As the years progressed, advancements in hardware architecture, such as the development of specialized hardware for machine learning tasks (like tensor processing units), continued to accelerate the impact of computational power on machine learning. These developments allowed for the exploration of even more sophisticated algorithms, the handling of larger datasets, and the deployment of real-time applications.
Big Data
Machine learning initially focused on algorithms that could learn from data and make predictions. Simultaneously, the growth of the internet and digital tech brought on the era of big data – data that's too vast and complex for traditional methods to handle. Enter data mining, a field that specializes in foraging through large datasets to discover patterns, correlations, and valuable information. Data mining techniques, such as clustering and association rule mining, were developed to reveal hidden insights within this wealth of data.
As computational power advanced, machine learning algorithms evolved to tackle the challenges of big data. These algorithms could now process and analyze enormous datasets efficiently. The integration of data mining techniques with machine learning algorithms enhanced their predictive power. For instance, combining clustering techniques with machine learning models could lead to better customer segmentation for targeted marketing.
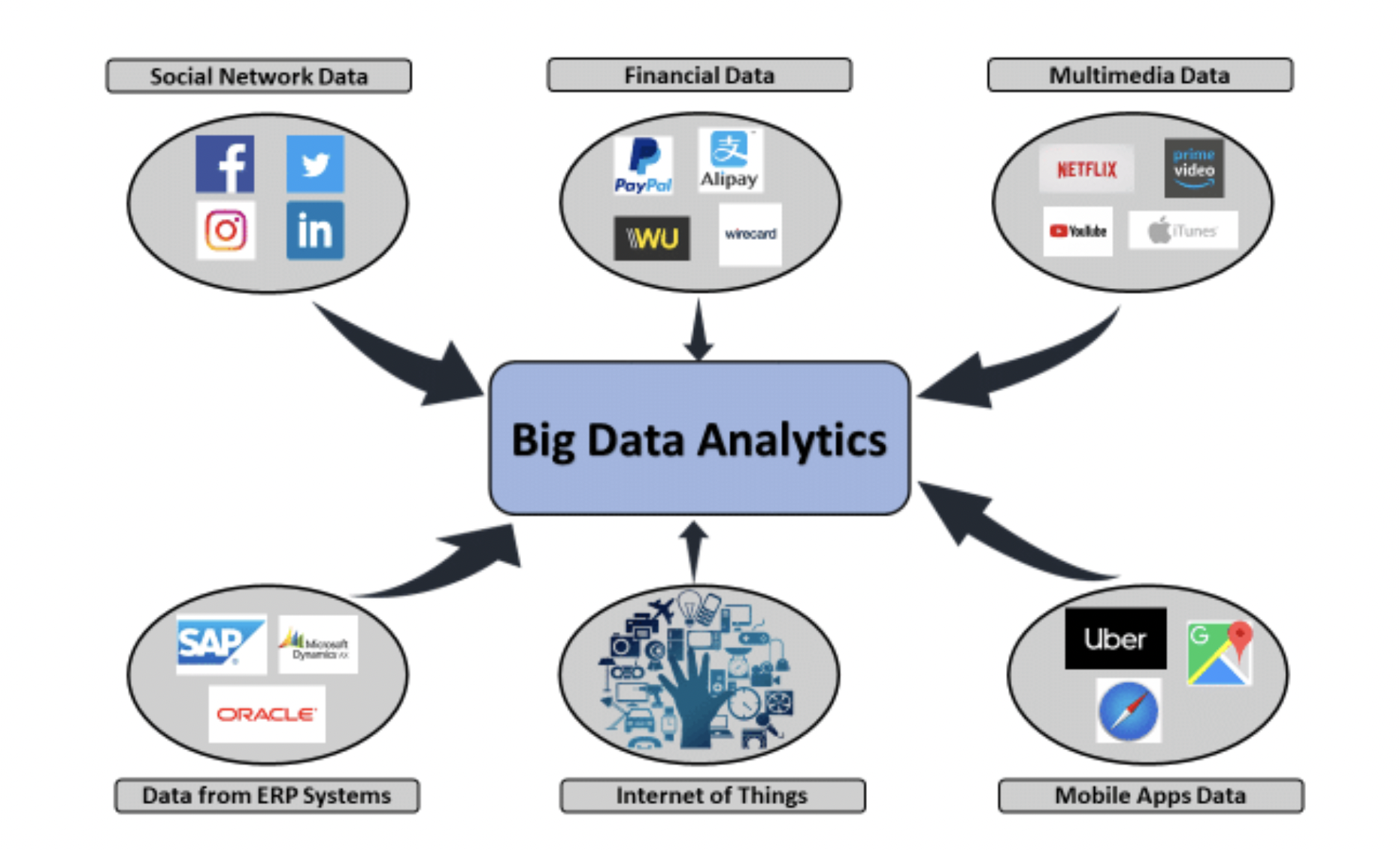
Data from all these sources advance ML algorithms every day. Source: Big Data: Ethics and Law, Rainer Lenz
Machine learning gets better the more learning it has a chance to do - so models trained on massive sets of data sourced from across the internet can become immensely powerful in a shorter amount of time due to their access to study materials.
Neural Networks and Deep Learning Revolution
Early Research
Early neural network research, spanning the 1940s to the 1960s, was characterized by pioneering attempts to emulate the human brain's structure and functions through computational models. The initial endeavors laid the groundwork for modern neural networks and deep learning. However, these early efforts encountered significant challenges that tempered their progress and widespread adoption.
Early neural networks were primarily confined to single-layer structures, which curtailed their capabilities. The limitation to linearly separable problems, like what the perceptron faced, hindered their potential to tackle real-world complexities involving nonlinear relationships. Training neural networks necessitated manual weight adjustments, rendering the process laborious and time-intensive. Additionally, the inability to address nonlinear relationships led to the infamous XOR problem (an exclusive or can't be calculated by a single layer), a seemingly straightforward binary classification task that eluded early neural networks.
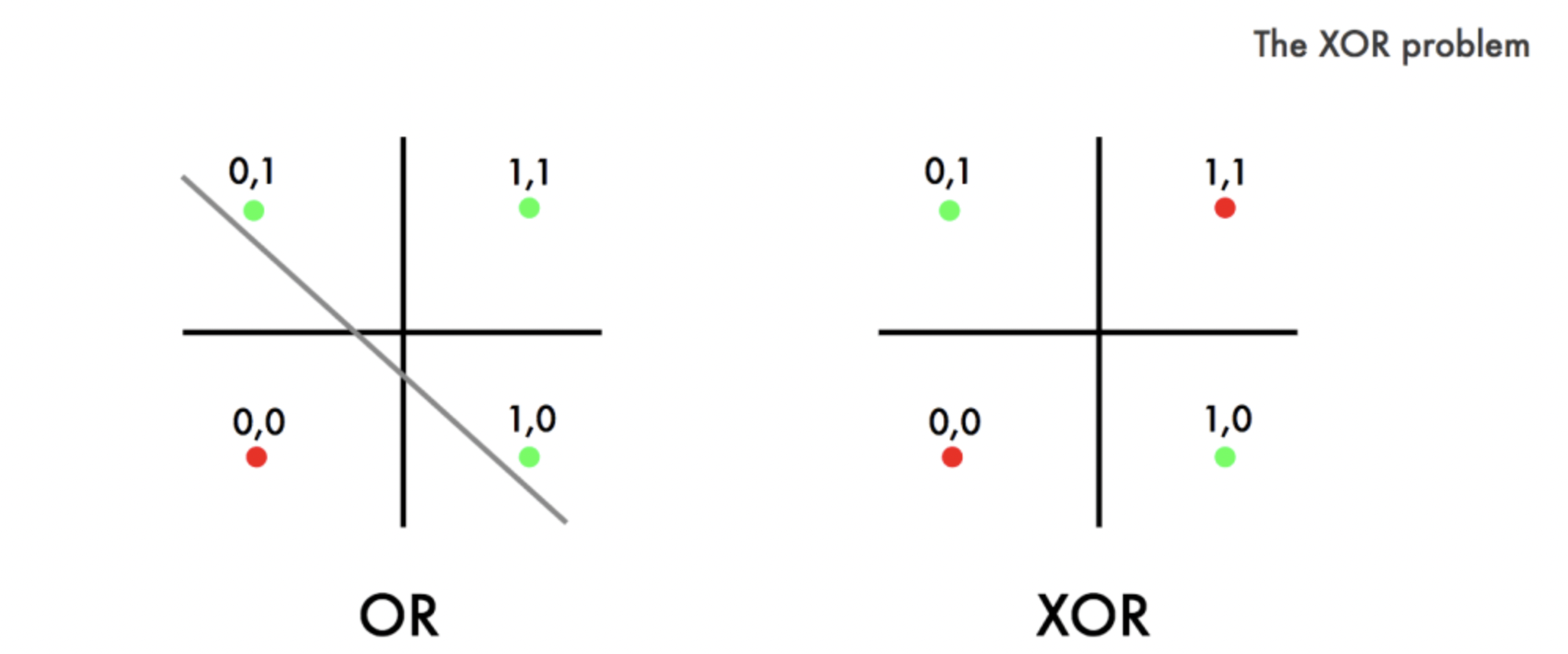
Source: dev.to
Notably, early neural network research lacked a strong theoretical foundation, and the mechanisms underlying the success or failure of these models remained unknown. This lack of theoretical understanding hindered advancements and contributed to the waning interest in neural networks during the late 1960s and early 1970s.
The Backpropagation Algorithm
The Backpropagation algorithm emerged as a solution to the problems that plagued early neural network research, catalyzing the revival of interest in neural networks and welcoming in the era of deep learning. This algorithm, which gained prominence in the 1980s but had its roots in the 70s, addressed critical challenges that had impeded neural networks' progress and potential.
The big challenge was the vanishing gradient problem, an obstacle that hindered the training of deep networks. While calculating weight updates within the network, the weight change is proportional to the partial derivative of the error function with respect to the current weight. When these gradients start getting small enough that the weight change no longer has an effect on the weight, you have a vanishing gradient problem. If it happens, the network will pretty much stop learning due to the algorithm no longer updating itself.
The Backpropagation algorithm provided a systematic mechanism to calculate gradients in reverse order, enabling efficient weight updates from the output layer back to the input layer. By doing so, it mitigated the vanishing gradient issue, allowing gradients to flow more effectively through the network's layers and the netowrk to continue updating itself as it "learns."
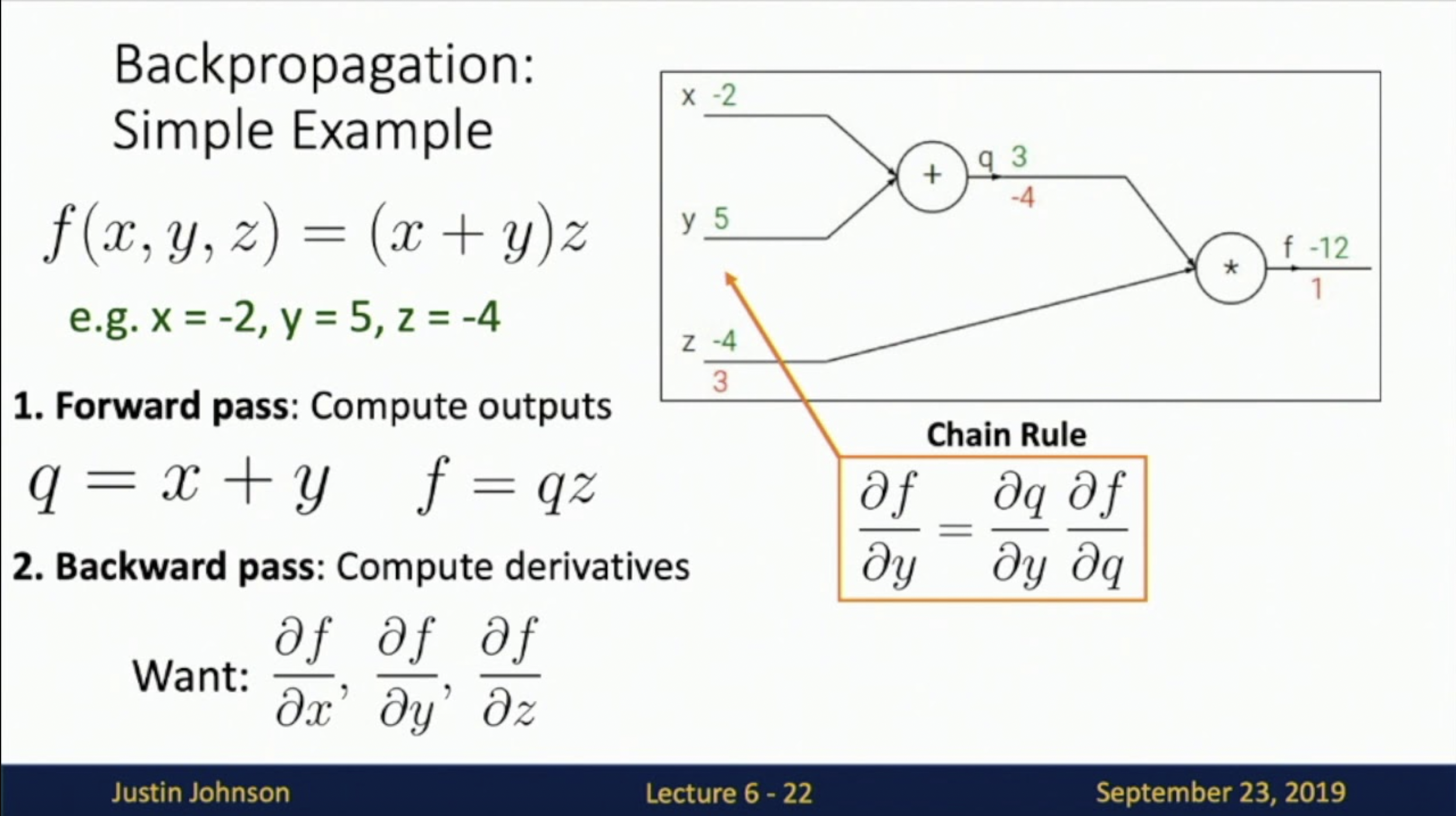
I haven't seen a differential equation since 2018. Source: Justin Johnson, University of Michigan
The Backpropagation algorithm unlocked the potential to train deeper networks, a feat that had eluded early neural network efforts. By enabling gradients to propagate backward, Backpropagation allowed for the adjustment of weights in deeper layers, thus enabling the construction of multi-layer architectures. This breakthrough marked a significant departure from the shallow models of the past and led to the development of sophisticated architectures that demonstrated exceptional promise in tasks like image recognition, natural language processing, and more.
Beyond overcoming specific challenges, the Backpropagation algorithm reignited interest in neural networks as a whole. Researchers realized that these models, empowered by Backpropagation's capabilities, could capture intricate relationships and patterns within data. This resurgence formed the foundation of the deep learning revolution, a period of exponential advancement in artificial intelligence driven by deep neural networks.
Deep Learning and Convolutional Neural Networks (CNNs)
The 2010s constituted a period of deep learning advancements, which brought about a substantial leap in the capabilities of neural networks. Standing out among these breakthroughs is the Convolutional Neural Network (CNN), a marvel that has particularly revolutionized image analysis and the field of computer vision. CNNs are uniquely tailored to fathom and interpret intricate features intrinsic to images. This emulation of the hierarchical structure and intrinsic correlations that underlie visual information is why they're so effective.
I actually did a project with this once in school using TensorFlow and Keras. I applied the texture of Van Gogh's Starry Night to a picture of a plane my brother had taken (thanks Kyle!), resulting in the image on the bottom:

+


The convolutional layers intricately dissect patterns through filter operations, capturing elemental features like edges and textures that previously were beyond the grasp of any sort of computational model. Following pooling layers downsize feature maps while retaining vital data. The journey culminates in fully connected layers that synthesize the assimilated features, yielding impressive results. CNN has proven to be adept at image classification, object detection, image generation, transfer learning, and more.
Other Important Milestones
- 1913: The Markov Chain is discovered.
- 1951: The first neural network machine, the SNARC is invented.
- 1967: The nearest neighbor algorithm is created, the start of basic pattern recognition.
- 1970: The neocognitron is discovered, a type of artificial neural network that will later inspire CNNs.
- 1985: NETtalk, a neural network that learns how to pronounce words the same way babies do, is developed.
- 1997: IBM's Deep Blue defeats chess champion Gary Kasparov in chess.
- 2002: Machine learning software library Torch is released.
- 2009: ImageNET, a large visual database, is created. Many credit ImageNet as the catalyst for the AI boom of the 21st century.
- 2016: Google's AlphaGo becomes the first computer to beat a professional human player in Go.
- 2022: Large-scale language model ChatGPT is released for public use.
Stay tuned in the coming weeks for more about machine learning's applications and how this revolution will affect you!
Using ML in your work? Remember an earlier iteration of it? Have thoughts and opinions on differential equations? Let us know in the comments!









{kind=link}
We could even go back as far as Bayes.
No mention of fuzzy logic? I had to laugh when I read the feature list of our washing machine -one of the top bullet points was that it uses fuzzy logic to evaluate the clothes' dirtiness.